
|
导读:英伟达畴昔十年靠GPU在“AI考试”阛阓开采的霸权,正在被“AI推理”需求所动摇。算力竞赛的焦点,依然从“谁能堆更多算力”转向了“谁能构建更优的经济模子”。这场由“AI推理成本”激勉的篡改,正在催生一个多元化的算力新格式。 英伟达正在从“端正制定者”,回荡为“牌桌上的玩家之一”。 畴昔几年,AI行业的算力武备竞赛,不错说便是英伟达显卡FLOP的晋升。从H100到Blackwell再到Vera Rubin,每一代新GPU的发布,都是在探索新的物理极限。 但当需求迟缓从计议的“大真金不怕火模子”到量入为主的“推理使用”时,成本问题运转露馅。
最近一段时刻,非GPU算力迟缓崛起。Anthropic与谷歌和AWS别离签下价值数百亿好意思元、各采购百万颗级别TPU和Trainium芯片;当Meta一边采购英伟达和AMD的GPU,一边又与谷歌签下数十亿好意思元的TPU租出契约;连OpenAI也在绕开英伟达,径直与Cerebras签下超100亿好意思元的算力契约。 这些都证实,AI天下的底层操作系统正在重构。TPU、LPU这些非GPU阶梯,运转反攻英伟达。 无法侧办法“推理税” {jz:field.toptypename/}英伟达畴昔的卓越,其实是在“考试”阶段。 考试,是一次性的、本钱密集型的“大兴土木”工程。插足数万张GPU,奢靡数月时刻和数亿好意思元,教化一个模子坚硬天下。在这个阶段,GPU凭借其遒劲的通用并行设想身手和进修的CUDA生态,是无可争议的王者。 但模子终究是要用的。推理,便是模子被考试好后,每一次对外提供奇迹的经过。ChatGPT的每一次问答,豆包生成的每张图片,都是一次推理。与一次性的考试不同,推理是抓续的、高频的、限制随用户量指数级增长的运营成本。
阛阓分析普遍以为,到2030年,推理将占据总计AI设想资源的75%,酿成一个2550亿好意思元的深广阛阓。 问题在于。为考试而生的GPU,在推理这件事上,后果并不经济。GPU的设想玄学是“隐晦量优先”,像一个巨大的知道场,能同期容纳千千万万的东谈主处理并行任务。 但在及时推理中,任务时时是串行的,比如生成式AI需要一个Token一个Token地输出。这就好比每次只让一个东谈主收支这个巨大的知道场,绝大部分座位(设想中枢)都在闲置,恭候数据从死力且远方的高带宽内存(HBM)中慢悠悠地搬运过来。这导致了极高的延迟和极低的单元后果。
对于数据中心而言,这意味着每一瓦特电力、每一普通毫米的芯片,都莫得被充分运用。 当用户限制达到数十亿,这种低效被放大成天文数字的成本。这笔“推理税”,总计AI公司都交给了英伟达。 一场针对“数据移动”的会剿 在英伟达GPU的“先天颓势”之上,一批新的设想架构应时而生。它们的设想玄学各不换取,但办法高度一致:杀死数据移动的成本。 1.谷歌TPU:为限制而生 谷歌早在2016年就推出了TPU(张量处理单元),但并非谷歌提前10年猜测了AI海浪,而是为了撑抓搜索、翻译、YouTube推选等大众性业务,必须处理推理的成本和能效问题。 TPU是ASIC(专用集成电路)的典范,它升天了GPU的通用性,只为以极致后果彭胀神经蚁集设想。
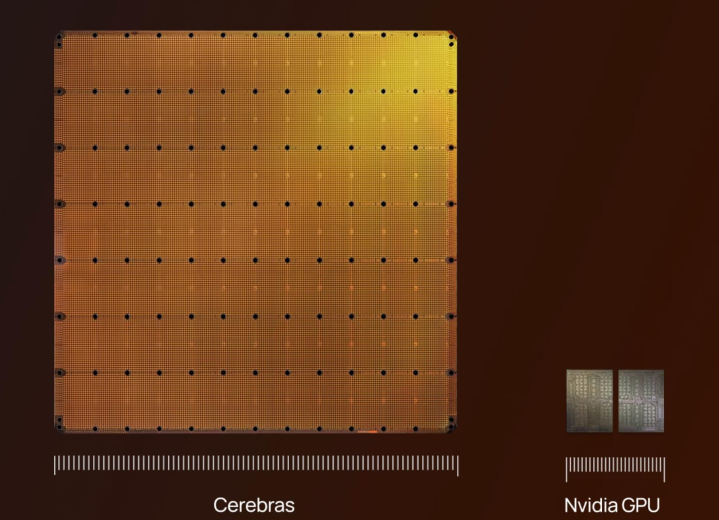
其中枢上风在于架构。TPU的“脉动阵列”让数据像在活水线上一样,在设想单元之间高效流动,无需世俗侦察主内存,从物理上减少了数据搬运的距离和能耗。比较之下,滚球app中国官网下载入口GPU需要箝制地从HBM中取请示、解码、彭胀,增多了多半支出。 为止是,在同类推理任务上,TPU的性价比不错作念到英伟达H100的4倍,能耗则低60-65%。 畴昔,谷歌将TPU算作“微妙兵器”,只供里面使用,构建了深厚的护城河。但当今,濒临外部客户的巨大需求,谷歌运转将TPU算力算作云奇迹出售。当Anthropic、Meta这些英伟达的顶级客户运转用真金白银投票给TPU时,英伟达高利润的交易模式便受到了径直胁迫。 2. Cerebras:挑战物理定律的“晶圆设想机” 如若说TPU是对GPU的小巧优化,那么Cerebras的Wafer-Scale Engine(WSE)则是一场透澈的物理篡改。 创举东谈主Andrew Feldman识破了英伟达集群模式的本色:用千千万万个散布的小芯片(GPU)组成一个“诬捏大脑”,再用NVLink、NVSwitch等死力的互联时刻,去弥补这些“大脑”之间物理距离带来的通讯规模。这是一种“横向扩展”,但数据移动的成本依然是根蒂瓶颈。 Cerebras聘请了完全相背的“纵向扩展”阶梯:如若数据移动是最大的敌东谈主,那就干脆不移动数据。他们莫得将12英寸的晶圆切割成数百个小芯片,而是完整地作念成了一个巨型芯片。
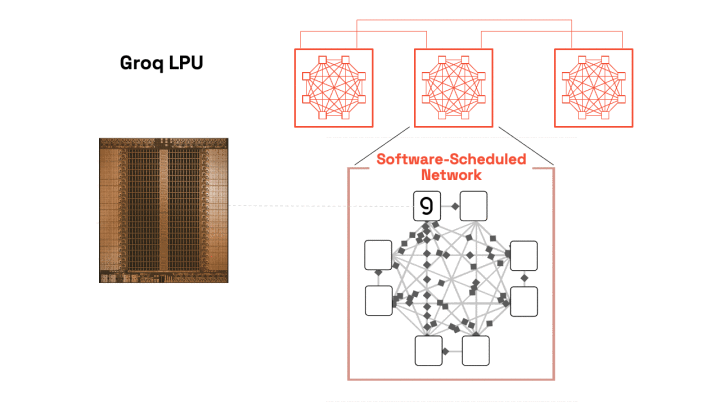
其第三代芯片WSE-3,面积是H100的56倍,集成了4万亿个晶体管和90万个AI中枢。最重要的是,它领有高达44GB的片上SRAM(刻下速率最快的存储器)。 这意味着,对于一个富有大的模子,着实总计的设想和数据都不错在这一块芯片里面完成,透澈摈弃了跨芯片、跨奇迹器的通讯。Nvidia的决议是“建更快的路”,Cerebras的决议是“取消通勤”。在处理大模子推理时,Cerebras的速率和能效比不错达到GPU集群的10倍以上。 恒久以来,爱游戏体育业界以为制造晶圆级芯片是不能能的,因为任何一个微细的制造颓势都会遗弃整块晶圆。Cerebras通过设想冗余中枢和可重构蚁集处理了这个问题,这本人便是一项工程古迹。 当OpenAI决定将畴昔中枢的推理负载大限制部署在Cerebras的系统上时,等于向阛阓宣告:这条路不仅走得通,况兼在坐褥环境中被讲解优于GPU。 3. Groq:为低延迟而生的“速率机器” Groq的创举东谈主Jonathan Ross,恰是谷歌第一代TPU芯片的中枢设想者。他创立Groq,其中枢居品LPU(说话处理单元),在念念想上是TPU的延迟和进化。LPU将“灭绝延迟”作念到了极致。 它不异遗弃了对外部HBM的依赖,将总计内存径直集成在设想单元掌握,并继承了“细则性盘曲”架构。GPU的运行是“动态”的,像一个杂乱的十字街头,由硬件盘曲器及时率领交通,这导致了彭胀时刻的不能展望性。而LPU是“静态”的,编译器在运行前就贪图好了每一个数据在每一个时钟周期的精准旅途,像一张无缺的列车时刻表。
这种架构,让Groq在处理LLM推理时,能跑出每秒数百以致上千Tokens的恐怖速率,而同期的GPU唯有几十到一百。对于需要及时交互的AI Agent等应用,这种低延迟是决定性的。 TPU、Cerebras、Groq,再加上亚马逊的Trainium、微软的Maia,它们共同组成了一个“非GPU阵营”:AI算力的畴昔,不再是GPU的鹤立鸡群,而是一个把柄不同应用场景(大限制考试、低成本推理、及时交互)聘请最优化架构的多元化生态。 英伟达:从制定例则到稳妥端正 濒临多方会剿,黄仁勋并莫得坐以待毙。英伟达豪掷200亿好意思元对Groq进行了“非排他性时刻许可”往还。 这与其说是收购,不如说是一场“软并吞”。英伟达付出了近三倍的溢价,买的不是Groq这家公司,而是Jonathan Ross和他的团队,以及他们手中那套最懂ASIC推理架构的时刻。
黄仁勋这样作念,正值讲解了他依然坚硬到,单靠GPU一条腿步碾儿的期间终泄露。 第一,他将阛阓上最可能颠覆其推理业务的寂然团队收入囊中,让他们在英伟达里面,将LPU的架构念念想与CUDA生态进行和会。不错猜测,在畴昔的架构中,英伟达很可能会推出异构芯片:在一块芯片上,既有效于考试的GPU中枢,也有挑升用于低延迟推理的LPU-like中枢。他必须补上我方最短的那块木板。 第二,即便整合不顺,他也达到了详确办法。一个被“招抚”的Groq,大脑依然来到了英伟达,剩下的体魄再也无法对英伟达组成致命胁迫。如若Groq被AMD粗略某个云巨头收购,那将是英伟达的恶梦。 这场往还揭示了英伟达的计谋回荡:从固守GPU的单一范式,转向构建一个包含不同架构的“算力兵器库”。英伟达不再是独一的兵器供应商,为了保住阛阓,它必须学会使用总计类型的兵器。 结尾之战:单元经济模子的顺利 当咱们将视线拉高,就会发现这场竞争的本色,依然超越了芯片本人。它是一场对于交易模式和单元经济模子的干戈。 头部AI公司,如Meta、Anthropic、OpenAI,它们的“去GPU化”计谋,更准确地说是“去单一供应商化”。它们采用的是一种“多供应商、多架构”夹杂策略。用英伟达的GPU进行前沿模子的探索和考试,因为CUDA生态的活泼性无可替代;同期,将大限制、进修的推理任务,迁徙到成本更低的TPU、Trainium或Cerebras上。 这种策略,让它们在与英伟达的谈判中得到了巨大的议价身手。它们不再是被迫接受报价的买家,而是不错用推行的迁徙案例来压低采购成本。同期,这也倒逼了总计这个词算力阛阓的交易模式创新。 畴昔的算力竞争,不再是残害地卖芯片。谷歌和AWS从不只独售卖TPU或Trainium芯片,而是将其打包在云奇迹中,以“每百万Tokens成本”或“每次API调用成本”来计费。Cerebras也推出了Condor Galaxy超等集群,径直以“ExaFLOPS考试工场”的形势对外接单。 它们卖的不是硬件,而是一个可展望、低成本的“AI坐褥身手”。客户热心的不再是底层用了什么芯片,而是最终的TCO(总领有成本)和投资酬劳率。 论断:一个更多元的AI畴昔 回到当先的见识。英伟达的GPU帝国根基依然踏实,尤其是在需要高度活泼性的模子辩论和考试领域,CUDA生态的护城河短期内无东谈主能及。但推理阛阓的经济律例,正在不能逆转地消弱其都备统治力。 畴昔的AI基础门径,将是一个异构设想的天下。GPU将转头其更擅长的领域,而TPU、LPU、WSE等专用ASIC将在各自擅长的领域大放异彩。 这些“非GPU”玩家的存在,迫使英伟达不得不再行扫视其集群架构的根蒂颓势。这也冲突了单一供应商的操纵,通过竞争压低了AI的准初学槛,开释了被死力算力成本扼制的创新活力。 这条新的阶梯,将通向一个更多元、更高效、成本更低的AI畴昔。在这场变革中,莫得不灭的王者,唯有箝制稳妥变化、为客户创造更优经济模子的实干家。 对英伟达来说,挑战才刚刚运转。对总计这个词AI天下来说,一个更健康的期间,正在到来。 |




 备案号:
备案号: